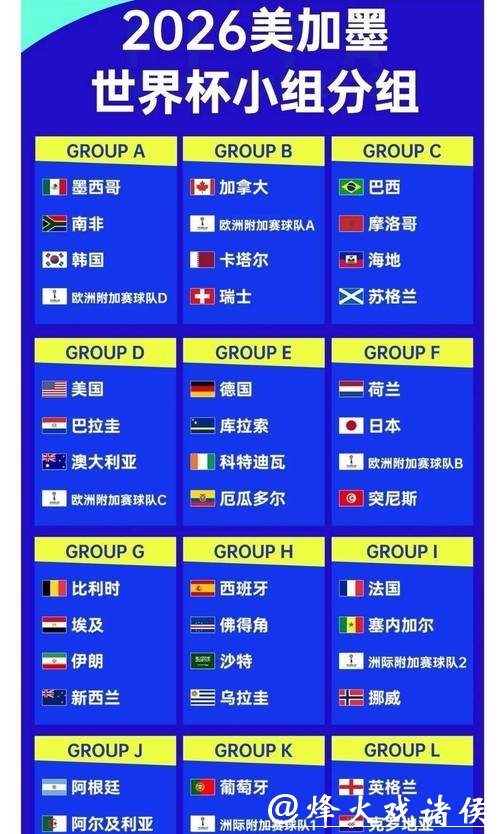
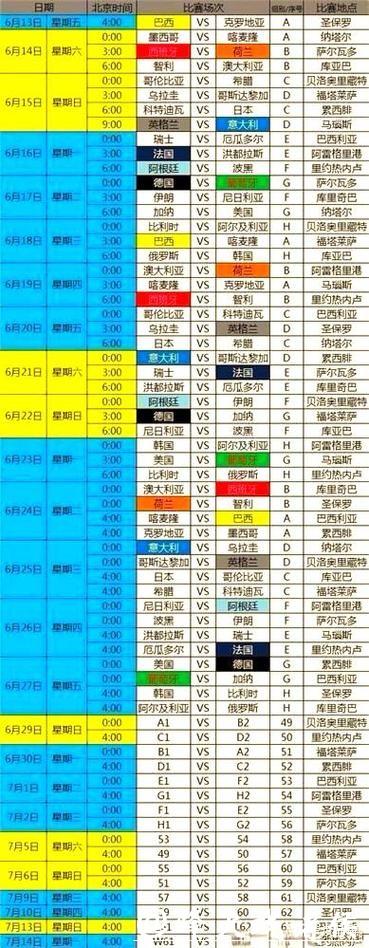
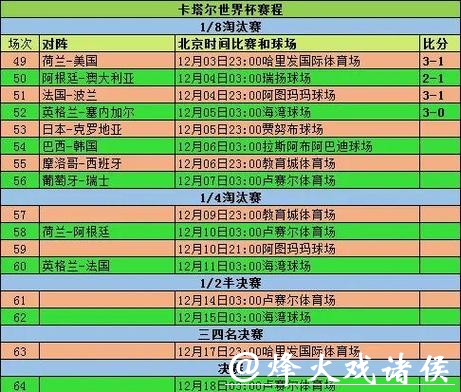
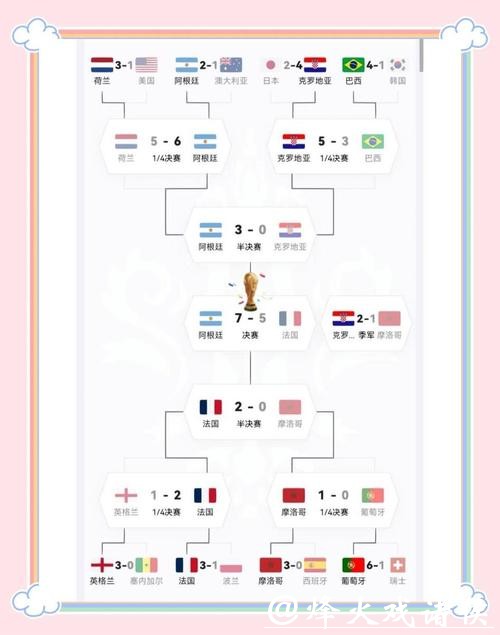
深入解析世界杯比赛预测模型的底层逻辑与实战思路
世界杯不仅是球迷四年一度的狂欢 也是数据建模和算法竞赛的天然舞台 在无数冷门与奇迹背后 预测模型试图给出一个理性答案 预测谁能小组出线 哪支球队更可能夺冠 某场比赛是胜平负还是进球大战 都离不开对数据的深入挖掘和对比赛本质的理解 真正有价值的世界杯比赛预测模型 并不是简单地将历史比分丢进算法里求个结果 而是要在数据 数学和足球理解之间找到一个动态平衡点 下面就从整体框架到细节方法 对世界杯比赛预测模型做一次相对系统的解析
从整体结构来看 一个相对完整的世界杯预测系统通常包括三个核心模块 数据获取与清洗 特征构建与选择 模型训练与评估 数据层解决的是模型看什么 特征层思考的是怎么“理解”比赛 模型层则决定了如何把理解转化成可执行的概率预测 在任何一步出现逻辑短板都会直接放大到最终结果 因此深入解析预测模型 本质上是在剖析一套系统工程而不是单一算法

在数据层面 世界杯比赛预测的第一步是定义什么是有效信息 常见的基础数据包括球队历史战绩 世界杯和洲际大赛的表现 球队在预选赛和热身赛中的进球 失球 场均射门 射正 控球率等指标 更细一点 会将对手强弱进行加权 例如击败一支世界排名前十的球队 权重大于大胜一支排名靠后的弱旅 除了球队数据 球员层面的信息同样关键 包括主力球员的出场率 伤病记录 场均关键传球 场均抢断 拦截以及预期进球xG和预期助攻xA 这些数据在俱乐部层面积累较多 但在世界杯场景下需要考虑适配问题 比如球员在俱乐部的战术角色与在国家队是否一致 位置是否前移或后撤 否则模型会出现偏差

数据获取之后 清洗与标准化是绕不过去的一步 缺失数据如何处理 异常值是否剔除 不同联赛 不同对手导致的数据分布差异如何校正 都会显著影响最终预测效果 例如 对于部分小国球队 历史世界杯样本极少 如果简单丢弃 会导致模型对冷门球队的预测极度保守 此时可以通过贝叶斯平滑 或结合洲际赛事的数据进行补充 以获得更稳定的分布估计 此外 时间维度也很关键 十年前的战绩对于当前世界杯的参考意义有限 因此很多模型会采用时间衰减权重 对近期两到三年内的比赛给予更高权重 以更好捕捉当下真实实力

在特征构建层面 一个高质量的世界杯比赛预测模型往往体现在特征工程上 而非仅仅依赖复杂算法 比如 常用的基础特征包括球队Elo或SPI评分 主客场或中立场标记 大赛经验 指数化的球队稳定性指标 还有球员平均年龄 阵容身高结构 对定位球攻防的依赖度等 更进阶的做法是构建相对特征 而不是绝对指标 例如 不直接使用A队的场均进球 而是使用“ A队场均进球减去B队场均失球 ” 或者“ A队的压迫强度与B队出球稳定性的差值 ” 这些相对特征更贴近对抗本质 对模型判别起到关键作用 在世界杯这种杯赛环境下 心理和战术因素也很难忽视 虽然难以完全量化 但可以间接表达 比如通过淘汰赛经验点数 主帅执教大赛场次 更换主帅时间距离世界杯的长短来刻画球队的战术成熟度和心理韧性
模型选择上 传统的泊松回归模型在足球预测领域有着悠久历史 因为进球数通常被视为近似泊松分布 可以基于两队攻击力和防守力估计每种比分的概率 从而得到胜平负的概率分布 然而 世界杯赛场上的现实往往更加复杂 球队在小组赛末轮可能只需要一分即可晋级 在淘汰赛可能更谨慎保守 这些策略性调整会让进球分布偏离标准泊松假设 因此越来越多的研究开始采用修正泊松模型 零膨胀泊松模型 或将泊松与层次贝叶斯框架结合 用以更好地融合先验信息和小样本不确定性
在机器学习与深度学习兴起之后 逻辑回归 随机森林 梯度提升树 XGBoost和LightGBM 被广泛应用于世界杯比赛预测中 这些方法在处理非线性特征组合和高维数据方面有明显优势 例如 可以自动从复杂的球队和球员指标中学习到某些非显式规则 但与此同时 模型越复杂 可解释性越差 对数据质量和特征选择越敏感 在世界杯这样小样本高噪声的场景下 一味追求复杂可能适得其反 因此很多实战团队会采用混合建模策略 即用简单的统计模型提供稳定的基线概率 用机器学习模型学习额外的偏离部分 再通过加权或集成方式获得最终结果
为了说明这种思路 可以看一个典型案例 某研究团队在上一届世界杯中构建了一个多层次预测系统 底层使用调整后的泊松模型预测每场比赛的进球分布 中层使用梯度提升树加入比赛情境特征 比如是否生死战 是否背靠背长途飞行 对手世界排名档位等 顶层则通过蒙特卡洛模拟对整个赛程进行上万次仿真 得出每支球队的晋级概率和夺冠概率 模型在小组赛阶段对胜平负的命中率接近70 对主要热门球队晋级情况预测较为准确 然而仍然错判了几场经典冷门 例如一支传统强队在小组赛提前出局 事后分析发现 模型低估了内部伤病集中爆发和战术混乱的影响 这个案例说明 再精细的模型也无法完全消除现实世界的不确定性 预测永远是概率而不是定论

围绕世界杯比赛预测模型还有一个经常被忽视但极其重要的环节 就是模型评估与校准 简单用命中率来评价往往会导致误解 如果模型给出强队获胜概率80 最终强队输了 并不代表模型一定错误 关键在于大量样本下 这类80的概率事件是否大约有八成真的发生 因此需要采用Brier分数 交叉熵对数损失 校准曲线等指标 对预测概率的可信度进行系统检验 此外 在世界杯这种周期性赛事中 还需要跨届评估模型的稳健性 看其在不同届世界杯 不同主办地和不同主流战术风格下 是否仍然保持合理表现
值得强调的是 深入解析世界杯比赛预测模型 并不是为了制造所谓“稳赢策略” 而是希望通过数据和算法 更接近比赛本身的真实结构 对于球队教练组来说 这样的模型能帮助识别潜在短板 比如定位球防守效率处于淘汰赛球队的下游 对某类高位逼抢球队容错率偏低 对此做有针对性的战术调整 对分析师和研究者而言 模型则是一种实验平台 可以验证战术趋势 是否真的从长远看影响胜负概率 例如高位压迫是否在体能消耗和抢回球权之间获得了净收益 对普通球迷和爱好者来说 理解这些模型的原理 则有助于在享受世界杯激情的同时 保持一份理性的视角 当看到冷门时 能意识到这往往是在低概率空间里的一次自然实现 而不是所有预测方法的集体失效 也正是这种理性与不确定性的交织 让世界杯比赛预测始终保持吸引力